purpose
Over-representation analysis (“enrichment analysis”) of RNA-seq data considering cDNA length effects with unsupported model organisms.
background
Among many transcriptome analysis platforms, transcriptome analysis by next-generation sequencing (RNA-seq) has been used widely among model and non-model organisms. In RNA-seq, number of reads mapped to reference cDNA sequences (or genes in genome sequences) is proportional to size of genes1. This effect should be corrected especially when enrichment analysis is performed because a gene category of your interest is enriched only because genes in the category are large in size. R/Bioconductor package GOseq handles this issue and I’ve been using it for my analysis2 . In my “Over-representation analysis” blog series, I would like to describe how to use the “GOseq” in model organmisms (such as Arabidopsis thaliana as a model plant) using GO terms (part1), or custom categories defied by users (part2), and non-model organisms in which a fasta file for cDNAs is available (part3). Furthermore, visualization of the enrichment summary in a heatmap will be described in part4 (instead of long tables!). For details in goseq, please read the origianl GOseq paper and papers cited the papers in PubMed.
# knitr::opts_chunk$set(echo = FALSE, error=TRUE)
library(goseq)
library(tidyverse)
library(readxl)GOseq analysis of Arabidopsis thaliana DEGs
Please download shade responsive genes Nozue (2018) PloS Genetics S2 Table1. Also download normalized read count file from the repository (click “Raw” button)
 or
or Obtaining Arabidopsis thaliana DEGs
# Unfortunately Arabidopsis thaliana was not supported by goseq.
head(supportedOrganisms())
# reading shade-responsive genes (1h shade treatent)
getwd()
genes.shade1h<-readxl::read_excel("2018-09-26-over-representation-analysis-1-goseq-with-arabidopsis-go-term_files/journal.pgen.1004953.s008.XLSX",sheet=1)
genes.shade1h.up <- genes.shade1h %>% filter(table.logFC>0 & table.FDR<1.0e-15) # Up regulated by shade. Play with table.FDR
genes.shade1h.down <- genes.shade1h %>% filter(table.logFC>0 & table.FDR<1.0e-15) # Down regualated by shade. Play with table.FDR check expression pattern of DEGs
# load read count data from downloaded repository
# myRNAseq.cpm<-read_csv("resources/knozue-sasphenotyping-b04217e6559b/SAS_analysis_Jan2014/R_scripts_data_objects/myRNAseq.cpm.csv") # change path for your file
# Another way is to load read count data from downloaded csv file
#myRNAseq.cpm<-read_csv("2018-09-26-over-representation-analysis-1-goseq-with-arabidopsis-go-term_files/myRNAseq.cpm.csv")
# Read directly from repository
myRNAseq.cpm<-read_csv("https://bitbucket.org/knozue/sasphenotyping/raw/b04217e6559bf953fb03b67071d793c23f112495/SAS_analysis_Jan2014/R_scripts_data_objects/myRNAseq.cpm.csv")
# format data for plot
genes.shade1h.up %>% left_join(myRNAseq.cpm,by=c("AGI"="X1")) %>% separate(Description,into="Description",sep=";",drop=TRUE) %>% unite(AGI_desc,c("AGI","Description")) %>% dplyr::select(-starts_with("table"),-`found in ATH1`,-starts_with("Kozuka")) -> plot.data
# plot: use labeller = label_wrap_gen(width=10) for multiple line in each gene name
p<-plot.data %>% gather(sample,value,-1) %>% separate(sample,c("genotype","trt","time_hr","rep"),sep="_") %>%
ggplot(aes(x=fct_relevel(trt,"Sun"),y=value,color=trt,shape=time_hr)) + geom_boxplot() + geom_jitter() + facet_wrap(AGI_desc~.,scale="free",labeller = label_wrap_gen(width=30),ncol=3)+theme(strip.text = element_text(size=6))
p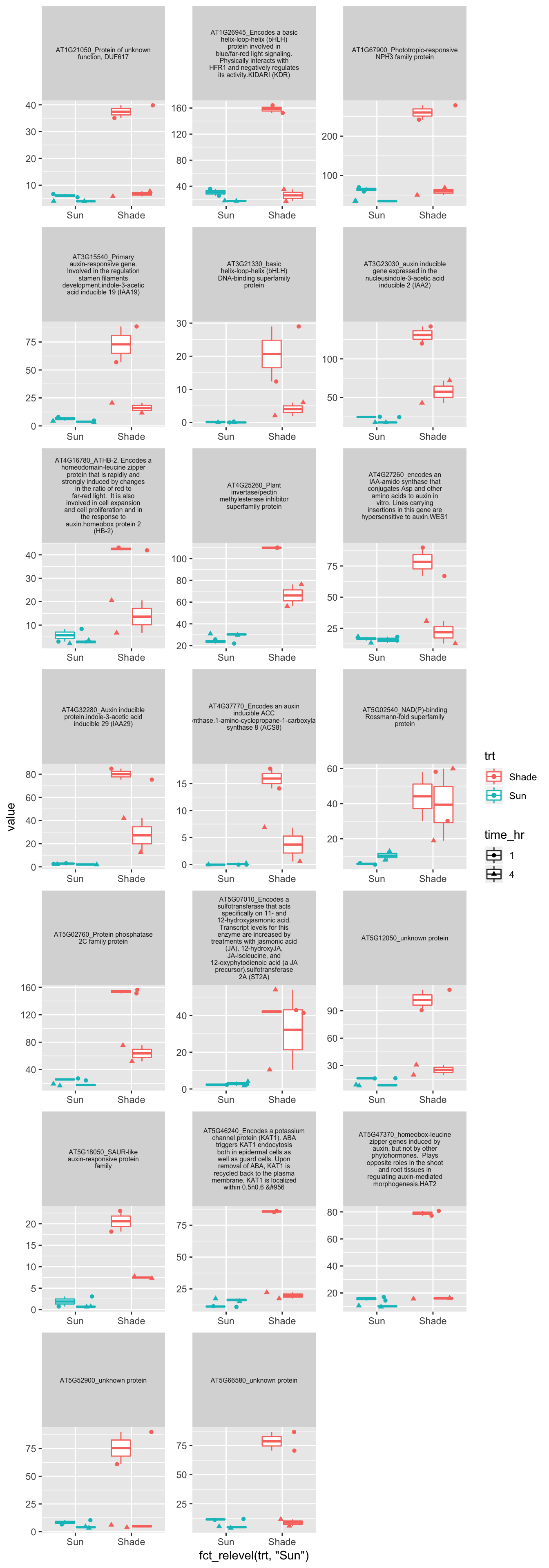
Usage of GOseq.ORA function
# GOseq
library(ShortRead);library(goseq);library(GO.db);library("annotate")
# Download cDNA sequence file from [Araport11] (https://www.arabidopsis.org/download_files/Sequences/Araport11_blastsets/Araport11_genes.201606.cdna.fasta.gz)
# At_cdna<-Biostrings::readDNAStringSet("2018-09-26-over-representation-analysis-1-goseq-with-arabidopsis-go-term_files/Araport11_genes.201606.cdna.fasta")
# donot use Araport11 version due to multiple splicing variants
# select only representative splicing variant
# Download cDNA sequence file (representative) from [TAIR10](https://www.arabidopsis.org/download_files/Sequences/TAIR10_blastsets/TAIR10_cdna_20110103_representative_gene_model_updated)
#system("gunzip -c 2018-09-26-over-representation-analysis-1-goseq-with-arabidopsis-go-term_files/TAIR10_cdna_20110103_representative_gene_model.gz > 2018-09-26-over-representation-analysis-1-goseq-with-arabidopsis-go-term_files/TAIR10_cdna_20110103_representative_gene_model")
#At_cdna<-Biostrings::readDNAStringSet("2018-09-26-over-representation-analysis-1-goseq-with-arabidopsis-go-term_files/TAIR10_cdna_20110103_representative_gene_model")
# download directly from TAIR
At_cdna<-Biostrings::readDNAStringSet("https://www.arabidopsis.org/download_files/Sequences/TAIR10_blastsets/TAIR10_cds_20110103_representative_gene_model_updated")
At_cdna## A DNAStringSet instance of length 27416
## width seq names
## [1] 2016 ATGGTTCAATATAATTTCA...AAAACCGACAGGCGTTGA AT1G50920.1 | Sym...
## [2] 546 ATGACTCGTTTGTTGCCTT...GTTGATTCTGGTACATAG AT1G36960.1 | Sym...
## [3] 1734 ATGGATTCAGAGTCAGAGT...GATTATATTCTCCAATGA AT1G44020.1 | Sym...
## [4] 1059 ATGTCGGTTCCTCCTAGAT...AGAGAGAGTGATAAATAA AT1G15970.1 | Sym...
## [5] 765 ATGGCGAGGGGAGAATCGG...ATGTTGAAAGGTTCTTGA AT1G73440.1 | Sym...
## ... ... ...
## [27412] 2019 GGGTTGAAGTTTAGACCGC...ACTACTAGTCTAGTCTAG ATMG00520.1 | Sym...
## [27413] 303 ATGGATCTTATCAAATATT...AATAGCATTCAAGGTTAA ATMG00650.1 | Sym...
## [27414] 384 ATGCTCCCCGCCGGTTGTT...CGATACTTAACTATATAA ATMG01330.1 | Sym...
## [27415] 573 ATGGATAACCAATTCATTT...CAGCGTAGCGACGGATAA ATMG00070.1 | Sym...
## [27416] 366 ATGGCATCAAAAATCCGCA...CCTTCTGCATACGCATAA ATMG00130.1 | Sym...# remove uncompressed file
#system("rm 2018-09-26-over-representation-analysis-1-goseq-with-arabidopsis-go-term_files/TAIR10_cdna_20110103_representative_gene_model")Run this chunck once to make Atgoslim.TAIR.BP.list.Rdata
## download TAIR version of [GOSLIM](http://www.arabidopsis.org/download/index-auto.jsp?dir=%2Fdownload_files%2FGO_and_PO_Annotations%2FGene_Ontology_Annotations)
## read me file is http://www.arabidopsis.org/download_files/GO_and_PO_Annotations/Gene_Ontology_Annotations/ATH_GO.README.txt
## directly read the file from TAIR
#test<-readr::read_tsv("https://www.arabidopsis.org/download_files/Subscriber_Data_Releases/TAIR_Data_20180630/ATH_GO_GOSLIM.txt.gz",skip=2,col_names=FALSE) # does not work
## store uncompressed version in box.com and download it
#test2<-readr::read_tsv("https://app.box.com/s/pdxbg2t8vpyatp4x9eewc13qaloa5i4r",skip=2,col_names=FALSE) # does not work.
## download file
download.file("https://www.arabidopsis.org/download_files/Subscriber_Data_Releases/TAIR_Data_20180630/ATH_GO_GOSLIM.txt.gz",destfile ="2018-09-26-over-representation-analysis-1-goseq-with-arabidopsis-go-term_files/ATH_GO_GOSLIM.txt.gz")
system("unzip -c 2018-09-26-over-representation-analysis-1-goseq-with-arabidopsis-go-term_files/ATH_GO_GOSLIM.txt.gz > 2018-09-26-over-representation-analysis-1-goseq-with-arabidopsis-go-term_files/ATH_GO_GOSLIM.txt") # this is not gunzip.
Atgoslim.TAIR<-read_tsv("2018-09-26-over-representation-analysis-1-goseq-with-arabidopsis-go-term_files/ATH_GO_GOSLIM.txt",skip=2,col_names = FALSE)## Parsed with column specification:
## cols(
## X1 = col_character(),
## X2 = col_character(),
## X3 = col_character(),
## X4 = col_character(),
## X5 = col_character(),
## X6 = col_character(),
## X7 = col_integer(),
## X8 = col_character(),
## X9 = col_character(),
## X10 = col_character(),
## X11 = col_character(),
## X12 = col_character(),
## X13 = col_character(),
## X14 = col_character(),
## X15 = col_date(format = "")
## )## Warning in rbind(names(probs), probs_f): number of columns of result is not
## a multiple of vector length (arg 1)## Warning: 6 parsing failures.
## row # A tibble: 5 x 5 col row col expected actual file expected <int> <chr> <chr> <chr> <chr> actual 1 21068 X15 "date lik… TAIR '2018-09-26-over-representation-analys… file 2 21068 <NA> 15 columns 16 colu… '2018-09-26-over-representation-analys… row 3 218961 X15 "date lik… pfsouth '2018-09-26-over-representation-analys… col 4 218961 <NA> 15 columns 16 colu… '2018-09-26-over-representation-analys… expected 5 218965 X15 "date lik… pfsouth '2018-09-26-over-representation-analys…
## ... ................. ... .......................................................................... ........ .......................................................................... ...... .......................................................................... .... .......................................................................... ... .......................................................................... ... .......................................................................... ........ ..........................................................................
## See problems(...) for more details.Atgoslim.TAIR %>% filter(X8=="P",X1=="AT4G38360") %>% dplyr::select(1,5,6,8,9,10)## # A tibble: 4 x 6
## X1 X5 X6 X8 X9 X10
## <chr> <chr> <chr> <chr> <chr> <chr>
## 1 AT4G38… vesicle-mediated transport t… GO:00… P transport IGI
## 2 AT4G38… negative regulation of brass… GO:19… P other cellular… IGI
## 3 AT4G38… negative regulation of brass… GO:19… P signal transdu… IGI
## 4 AT4G38… vacuole organization GO:00… P cell organizat… IGIAtgoslim.TAIR.BP <-Atgoslim.TAIR%>% filter(X8=="P")
Atgoslim.TAIR.BP.list<-tapply(Atgoslim.TAIR.BP$X6,Atgoslim.TAIR.BP$X1,c)
save(Atgoslim.TAIR.BP.list,file=file.path("2018-09-26-over-representation-analysis-1-goseq-with-arabidopsis-go-term_files","Atgoslim.TAIR.BP.list.Rdata"))
system("rm 2018-09-26-over-representation-analysis-1-goseq-with-arabidopsis-go-term_files/ATH_GO_GOSLIM.txt*") # removce both filesGOseq.Atgoslim.BP.list.ORA function
This function is used to calculate GO ORA results multiple times.
load("2018-09-26-over-representation-analysis-1-goseq-with-arabidopsis-go-term_files/Atgoslim.TAIR.BP.list.Rdata")
head(Atgoslim.TAIR.BP.list)## $`18S RRNA`
## [1] "GO:0006412" "GO:0006412" "GO:0006412"
##
## $`25S RRNA`
## [1] "GO:0043043" "GO:0043043"
##
## $`5.8S RRNA`
## [1] "GO:0043043" "GO:0043043"
##
## $AAN
## [1] "GO:0007623"
##
## $AAR1
## [1] "GO:0006970" "GO:0006970" "GO:0040029"
##
## $AAR2
## [1] "GO:0009845" "GO:0040029"GOseq.Atgoslim.BP.list.ORA<-function(genelist,padjust=0.05,ontology="BP",custom.category.list=Atgoslim.TAIR.BP.list,cdna=At_cdna) { # return GO enrichment table, padjus, padjust=0.05.
bias<-nchar(cdna)
names(bias)<-tibble(AGI=names(cdna)) %>% separate(AGI,into="AGI2",pattern="|",extra="drop") %>% dplyr::select(AGI2) %>% as_vector()
table(duplicated(names(bias)))
#TF<-(names(bias) %in% genelist)*1
TF<-as.integer(names(bias) %in% genelist)
names(TF)<-names(bias)
#print(TF)
pwf<-nullp(TF,bias.data=bias)
#print(pwf$DEgenes)
GO.pval <- goseq(pwf,gene2cat=custom.category.list,use_genes_without_cat=TRUE) # format became different in new goseq version (021111). Does not work (042716)
#head(GO.pval)
if(ontology=="BP") {
GO.pval2<-subset(GO.pval,ontology=="BP")
} else if(ontology=="CC") {
GO.pval2<-subset(GO.pval,ontology=="CC")
} else {
GO.pval2<-subset(GO.pval,ontology=="MF")
}
# calculating padjust by BH
GO.pval2$over_represented_padjust<-p.adjust(GO.pval2$over_represented_pvalue,method="BH")
if(GO.pval2$over_represented_padjust[1]>padjust) return("no enriched GO")
else {
enriched.GO<-GO.pval2[GO.pval2$over_represented_padjust<padjust,]
print("enriched.GO is")
print(enriched.GO)
## write Term and Definition
for(i in 1:dim(enriched.GO)[1]) {
if(is.null(Term(GOTERM[enriched.GO[i,"category"]]))) {next} else {
enriched.GO$Term[i]<-Term(GOTERM[[enriched.GO[i,"category"]]])
enriched.GO$Definition[i]<-Definition(GOTERM[[enriched.GO[i,"category"]]])
}
}
return(enriched.GO)
}
}GO.seq
# genes.shade1h.up
GOseq.Atgoslim.BP.list.ORA(genelist=genes.shade1h.up$AGI)## Using manually entered categories.## Calculating the p-values...## 'select()' returned 1:1 mapping between keys and columns
## [1] "enriched.GO is"
## category over_represented_pvalue under_represented_pvalue numDEInCat
## 969 GO:0009734 1.270089e-09 1 6
## 968 GO:0009733 1.442317e-09 1 7
## 922 GO:0009641 2.439352e-07 1 3
## numInCat term ontology
## 969 161 auxin-activated signaling pathway BP
## 968 304 response to auxin BP
## 922 17 shade avoidance BP
## over_represented_padjust
## 969 2.728864e-06
## 968 2.728864e-06
## 922 3.076836e-04## category over_represented_pvalue under_represented_pvalue numDEInCat
## 969 GO:0009734 1.270089e-09 1 6
## 968 GO:0009733 1.442317e-09 1 7
## 922 GO:0009641 2.439352e-07 1 3
## numInCat term ontology
## 969 161 auxin-activated signaling pathway BP
## 968 304 response to auxin BP
## 922 17 shade avoidance BP
## over_represented_padjust Term
## 969 2.728864e-06 auxin-activated signaling pathway
## 968 2.728864e-06 response to auxin
## 922 3.076836e-04 shade avoidance
## Definition
## 969 A series of molecular signals generated by the binding of the plant hormone auxin to a receptor, and ending with modulation of a downstream cellular process, e.g. transcription.
## 968 Any process that results in a change in state or activity of a cell or an organism (in terms of movement, secretion, enzyme production, gene expression, etc.) as a result of an auxin stimulus.
## 922 Shade avoidance is a set of responses that plants display when they are subjected to the shade of another plant. It often includes elongation, altered flowering time, increased apical dominance and altered partitioning of resources. Plants are able to distinguish between the shade of an inanimate object (e.g. a rock) and the shade of another plant due to the altered balance between red and far-red light in the shade of a plant; this balance between red and far-red light is perceived by phytochrome.see R scripts for vignett
Session info
sessionInfo()## R version 3.5.1 (2018-07-02)
## Platform: x86_64-apple-darwin15.6.0 (64-bit)
## Running under: macOS 10.14.3
##
## Matrix products: default
## BLAS: /Library/Frameworks/R.framework/Versions/3.5/Resources/lib/libRblas.0.dylib
## LAPACK: /Library/Frameworks/R.framework/Versions/3.5/Resources/lib/libRlapack.dylib
##
## locale:
## [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
##
## attached base packages:
## [1] parallel stats4 stats graphics grDevices utils datasets
## [8] methods base
##
## other attached packages:
## [1] annotate_1.58.0 XML_3.98-1.16
## [3] GO.db_3.6.0 AnnotationDbi_1.42.1
## [5] ShortRead_1.38.0 GenomicAlignments_1.16.0
## [7] SummarizedExperiment_1.10.1 DelayedArray_0.6.6
## [9] matrixStats_0.54.0 Biobase_2.40.0
## [11] Rsamtools_1.32.3 Biostrings_2.48.0
## [13] XVector_0.20.0 BiocParallel_1.14.2
## [15] bindrcpp_0.2.2 rtracklayer_1.40.6
## [17] GenomicRanges_1.32.7 GenomeInfoDb_1.16.0
## [19] IRanges_2.14.12 S4Vectors_0.18.3
## [21] BiocGenerics_0.26.0 readxl_1.1.0
## [23] forcats_0.3.0 stringr_1.3.1
## [25] dplyr_0.7.7 purrr_0.2.5
## [27] readr_1.1.1 tidyr_0.8.2
## [29] tibble_1.4.2 ggplot2_3.1.0
## [31] tidyverse_1.2.1 goseq_1.32.0
## [33] geneLenDataBase_1.16.0 BiasedUrn_1.07
##
## loaded via a namespace (and not attached):
## [1] nlme_3.1-137 bitops_1.0-6 lubridate_1.7.4
## [4] bit64_0.9-7 RColorBrewer_1.1-2 progress_1.2.0
## [7] httr_1.3.1 tools_3.5.1 backports_1.1.2
## [10] utf8_1.1.4 R6_2.3.0 DBI_1.0.0
## [13] lazyeval_0.2.1 mgcv_1.8-25 colorspace_1.3-2
## [16] withr_2.1.2 tidyselect_0.2.5 prettyunits_1.0.2
## [19] curl_3.2 bit_1.1-14 compiler_3.5.1
## [22] cli_1.0.1 rvest_0.3.2 xml2_1.2.0
## [25] labeling_0.3 bookdown_0.9 scales_1.0.0
## [28] digest_0.6.18 rmarkdown_1.11 pkgconfig_2.0.2
## [31] htmltools_0.3.6 rlang_0.3.0.1 rstudioapi_0.8
## [34] RSQLite_2.1.1 bindr_0.1.1 hwriter_1.3.2
## [37] jsonlite_1.6 RCurl_1.95-4.11 magrittr_1.5
## [40] GenomeInfoDbData_1.1.0 Matrix_1.2-15 fansi_0.4.0
## [43] Rcpp_1.0.0 munsell_0.5.0 stringi_1.2.4
## [46] yaml_2.2.0 zlibbioc_1.26.0 plyr_1.8.4
## [49] grid_3.5.1 blob_1.1.1 crayon_1.3.4
## [52] lattice_0.20-35 haven_1.1.2 GenomicFeatures_1.32.3
## [55] hms_0.4.2 knitr_1.21 pillar_1.3.0
## [58] biomaRt_2.36.1 glue_1.3.0 evaluate_0.12
## [61] blogdown_0.10 latticeExtra_0.6-28 modelr_0.1.2
## [64] cellranger_1.1.0 gtable_0.2.0 assertthat_0.2.0
## [67] xfun_0.4 xtable_1.8-3 broom_0.5.0
## [70] memoise_1.1.0References